Gisteren en vandaag was ik bezig met een woordfrequentielijst van het SoNaR-corpus (Oostdijk et al., 2013). Die lijst heb ik nodig om de Lexical Diversity-tool uit te breiden, maar ik heb het SoNaR vast als referentiecorpus toegevoegd aan de Keyword Analysis-tool.
Je kunt nu dus kiezen om trefwoorden in je (Nederlandse) tekst op te sporen door de tekst te vergelijken met het toch wel oude en veel kleinere CONDIV-corpus, of met het SoNaR-corpus. Andere beschikbare referentiecorpora zijn het BNC voor het (Brits) Engels, een Nederlandstalig popcorpus en een eveneens Nederlandstalig rapcorpus. Je kunt uiteraard ook nog steeds zelf een referentiecorpus toevoegen – dat is makkelijker dan je wellicht denkt!
In de onderstaande afbeelding kun je zien dat bijvoorbeeld het woord herkomstlanden significant vaker voorkomt in het NOS-artikel Onderzoek: deel collectie Oranjes mogelijk onrechtmatig verkregen dan in het SoNaR-corpus en dus iets zegt over de het artikel; het is een trefwoord of keyword.
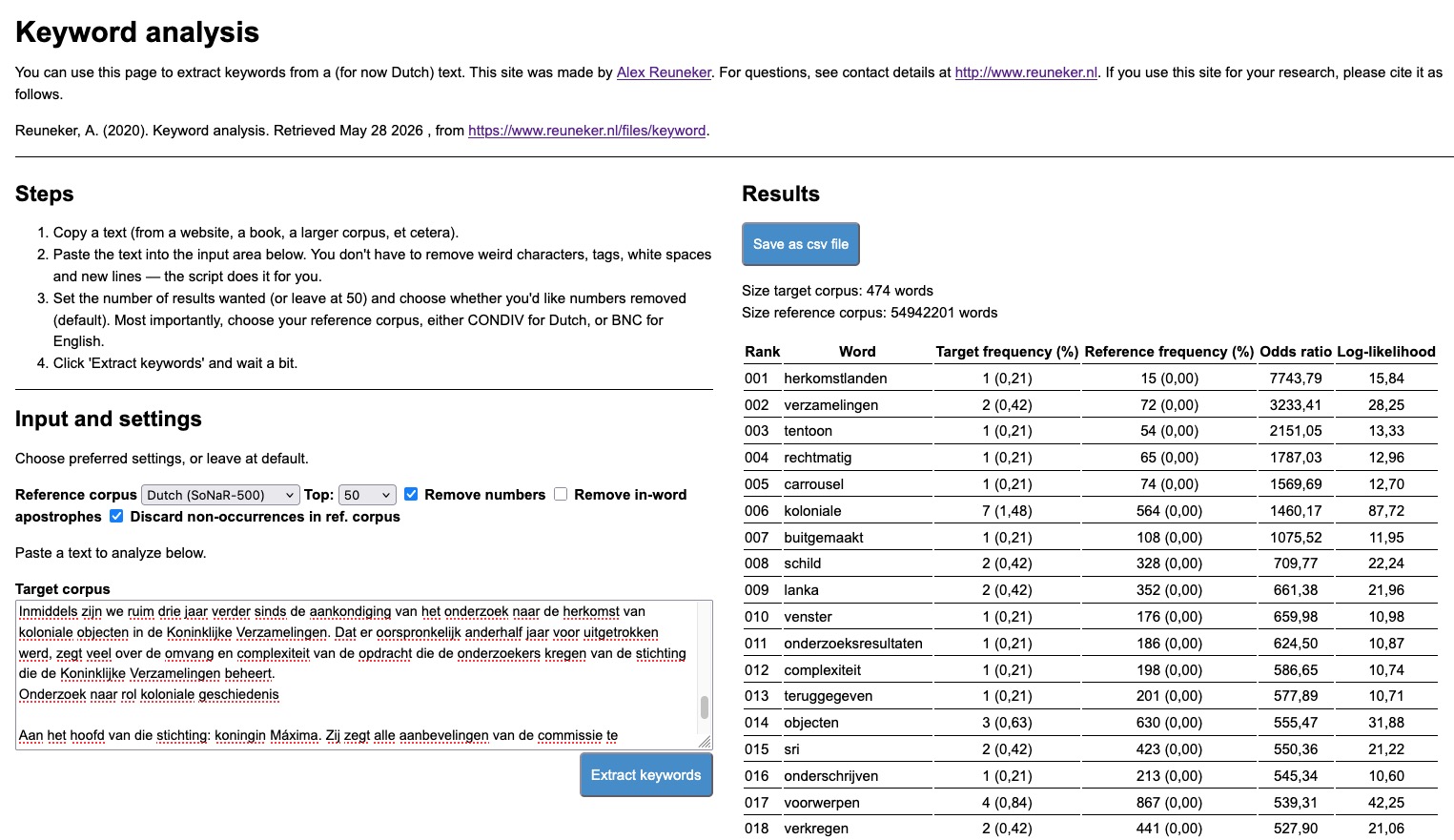
Trefwoorden in vergelijking met het SoNaR-corpus
Opmerkingen bij deze toevoeging zijn dat alleen Nederlandse krantenteksten zijn gebruikt voor de frequentielijst en, met het oog op processing in JavaScript en bestandsgroottes, alleen woorden die tien keer of vaker voorkwamen zijn meegenomen.
Je kunt de uitgebreide tool uiteraard direct gebruiken op https://www.reuneker.nl/files/keyword.



