I added a measure (somewhat) known as 'lexical coverage' to the Lexical Diversity Tool. This measure represents the percentage of words that occur in a list words from all Dutch newspaper texts in the SoNaR-500 corpus that, together, make up for 77 percent of all tokens in that corpus (although other corpora are used, see Staphorsius, 1994; Kraf, Lentz & Pander Maat, 2011). The higher this percentage, the easier the text, because more words may be supposed to be read before and thus 'known'. Although this definitely says something about the lexical diversity (perhaps indirectly) of a text, it is used primarily to assess the reading difficulty of a text (see also Adolphs & Schmitt, 2003; Van Zeeland & Schmitt, 2013).
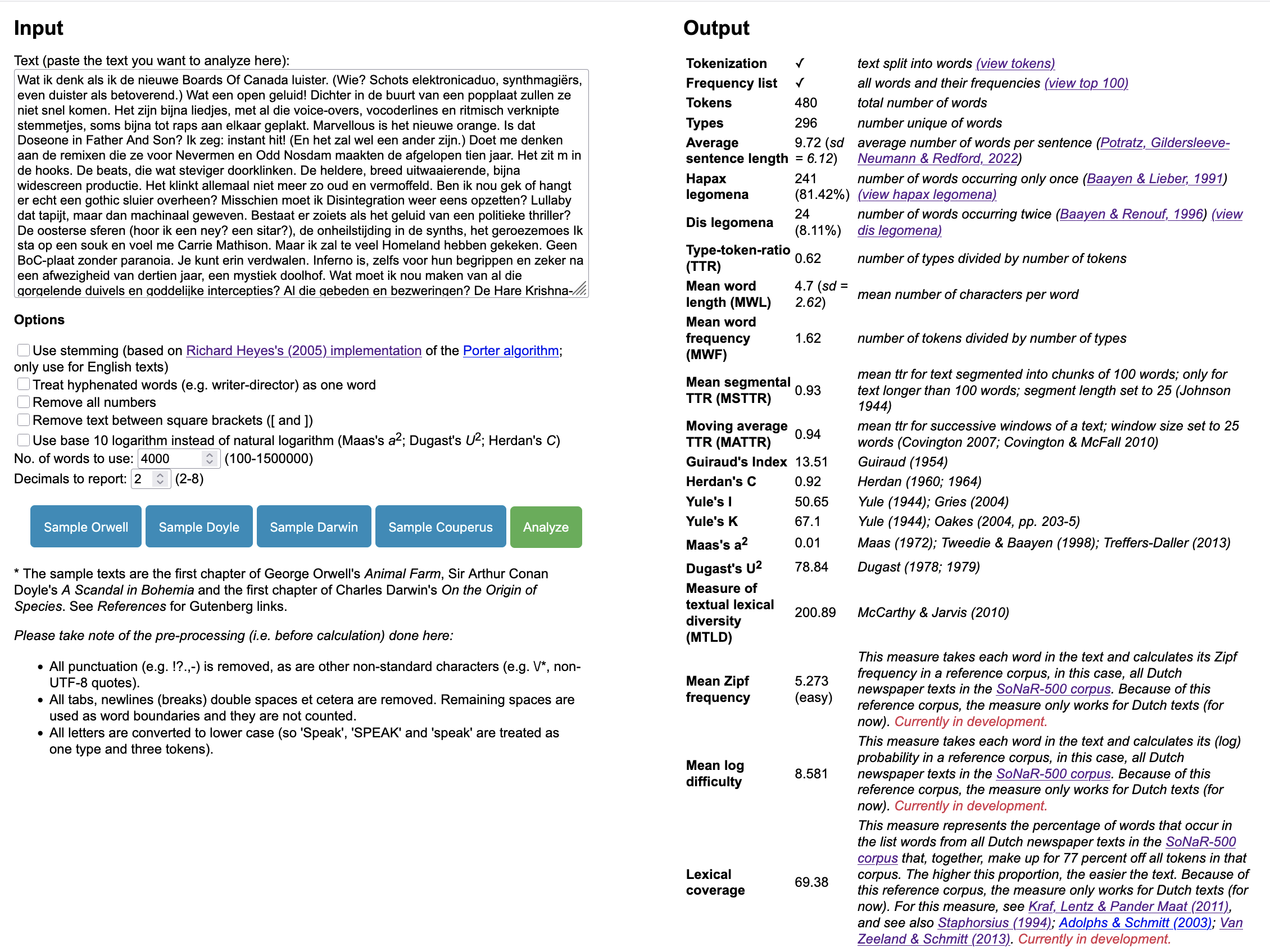
Lexical coverage added to Lexical Diversity Tool
Because I have used of the (Dutch newspaper subcorpus of the) SoNaR-500 as a reference corpus, the measure only works for Dutch texts – for now at least. Although the implementation is still a bit rough, it is workable and correct, but be aware it is still in development.