In samenwerking met Livia Rijkels voor Jong Neerlandistiek. Dit stuk is een bewerking van een paper dat Livia schreef voor de eerstejaarscursus Taal & Media, onderdeel van de bachelor Nederlandse Taal & Cultuur aan de Universiteit Leiden.
Lieke Marsman, voormalig Dichter des Vaderlands (2021-2023), overleed deze week op vijfendertigjarige leeftijd. Ze schreef meerdere dichtbundels, een roman en een filosofische essaybundel, die allemaal geprezen werden om de experimentele stijl en creatieve omgang met taal.

Gedichten en een essay in Marsmans 'De volgende scan duurt vijf minuten' (2018). Afbeelding van Uitgeverij Pluim.
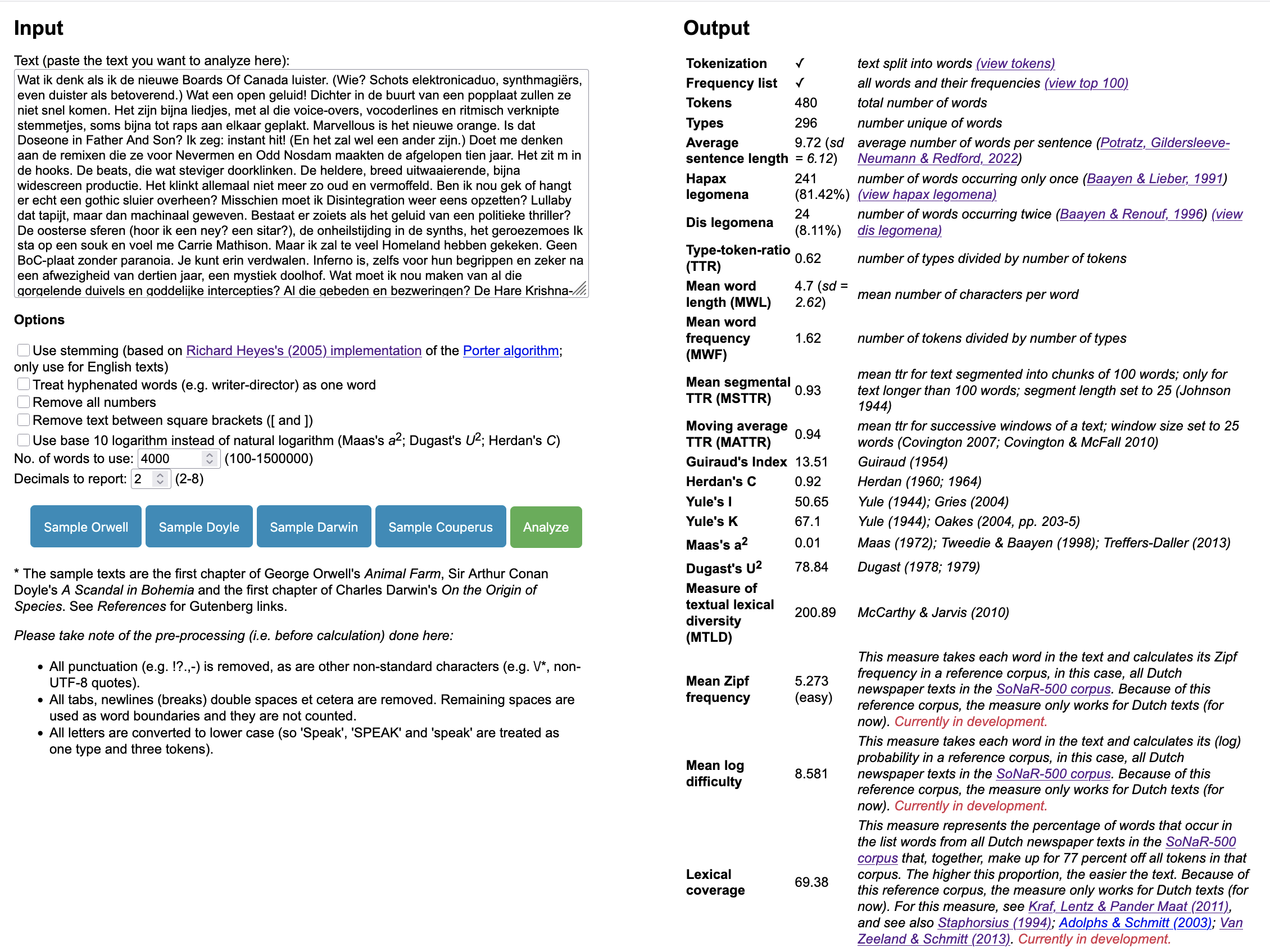
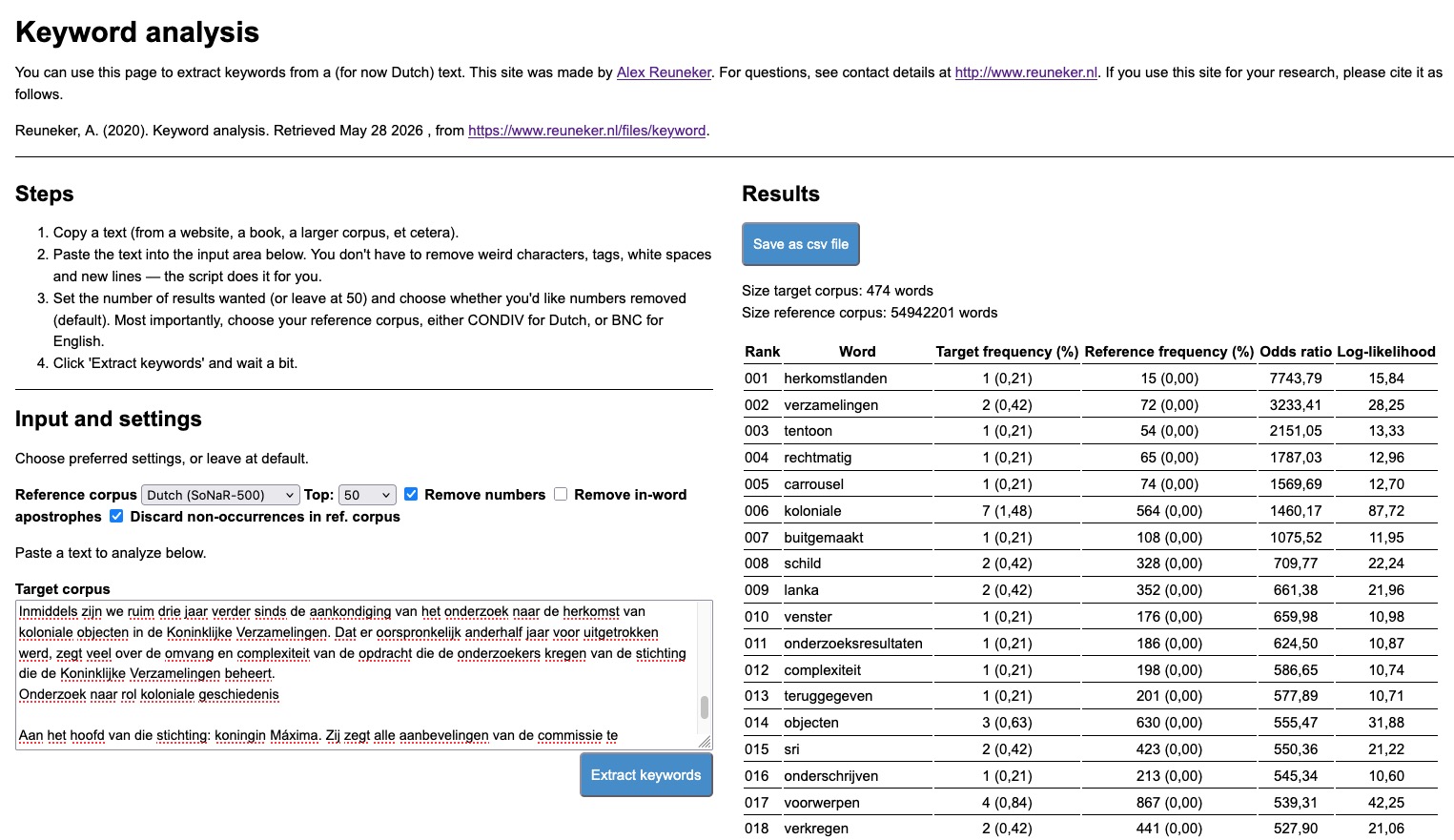
Vaak wordt gedacht dat poëtisch taalgebruik afwijkend en ingewikkeld is (Van Alphen, Duyvendak, Meijer & Peperkamp, 1996). Marsmans diverse oeuvre nodigt uit om te bekijken in hoeverre de woordenschat in haar dichtwerk afwijkt van haar proza en essayistisch werk. Om dat te onderzoeken, stelde ik voor het eerstejaarsvak Taal & Media drie kleine steekproeven samen: willekeurige selecties van steeds tien pagina’s uit de dichtbundel In mijn mand (2021), de roman Het tegenovergestelde van een mens (2017) en de essaybundel Op een andere planeet kunnen ze me redden (2025). Voor elke pagina in de steekproeven berekende ik de lexicale diversiteit in termen van MTLD of Measure of Textual Lexical Diversity, een maat die goed bestand is tegen verschillen in tekstlengte en lokale woordherhaling (zie Reuneker, Waszink & Van der Wouden, 2017). De metingen vergeleek ik door middel van een ANOVA-toets, om te kijken of ze, per genre in Marsmans werk, verschilden. In figuur 1 zie je dat er inderdaad verschillen zijn, maar die blijken (net) niet significant (F(2, 27) = 2.84, p = 0.07).
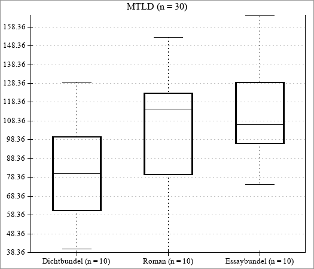
Figuur 1. MTLD-scores in Marsmans poëzie, roman en essays
Het verraste me enigszins dat Marsmans dichtwerk in In mijn mand het laagst scoort op lexicale diversiteit (81,72), gevolgd door de roman Het tegenovergestelde van een mens (102,18) en de essays in Op een andere planeet kunnen ze me redden (114,67). In figuur 1 is echter te zien dat de waarden in de steekproeven flinke variatie vertonen en dat de genres overlappen. Uit post-hocvergelijkingen blijkt dan ook dat de drie genres bij Marsman onderling niet significant verschillen in woordenschat.
De resultaten van dit kleine onderzoekje plaatsen een (eveneens kleine) kanttekening bij het idee dat poëtisch taalgebruik wezenlijk anders is dan ‘ander taalgebruik’. Het werk van Marsman laat dat, ook in de week van haar veel te vroege dood, goed zien. Zij leek zich niet te conformeren aan genreconventies: in haar dichtwerk noemt ze filosofen en hun denkwijzen, in de roman staan sommige hoofdstukken in dichtvorm en zowel de roman als de essaybundel bevat persoonlijke dagboekfragmenten, wederom met filosofische mijmeringen.
Wat de resultaten wellicht laten zien, is niet de afwezigheid van verschillen in woordenschat tussen genres, maar de aanwezigheid van Marsmans eigen, consistente stijl die door genregrenzen heen breekt. Zo schreef NRC vandaag dat haar poëzie ‘altijd helder, fris en toegankelijk’ was, ‘zonder daarbij hoge barrières of drempels op te werpen. […] Voor haar essayistiek gold hetzelfde […].’ Hoewel woordgebruik invloed heeft op de beeldvorming van literatuur, liet Lieke Marsman in haar werk zien dat je je niet hoeft te houden aan genreconventies, dat je de grenzen zelf bepaalt. Dat woorden essentieel zijn, zei ze zelf misschien wel het treffendst in De volgende scan duurt vijf minuten (2018):
Op andere momenten word ik overspoeld door wanhoop van de ergste soort, de soort die zich karakteriseert door een gebrek aan woorden: wanhoop die je alleen nog maar kunt omschrijven met het woord wanhoop.
De waarde van een tekst zit niet in het meetbare, in een toch enigszins afstandelijke benadering als lexicale diversiteit, maar in de daadwerkelijke, individuele lezing. In Zomergasten (2022) zei Marsman: ‘Ik wil een oproep tot leven zijn’. Laat dit stukje, ter nagedachtenis aan Lieke Marsman, een bescheiden oproep tot lezen zijn, een oproep haar werk – gedicht, verhaal of essay – er dit weekend nog eens bij te pakken en de woorden, haar woorden, op ons in te laten werken.
Livia Rijkels is student Nederlandse Taal en Cultuur aan de Universiteit Leiden. Dit artikel is bewerking die zij met Alex Reuneker maakte van ze een paper dat zij schreef voor zijn eerstejaarscursus Taal & Media.