De laatste looptraining voor de Zestig van Texel zit erop – vanmorgen deed ik een nog korte intervaltraining (6 keer 400 meter op 3:40) en ik voelde me aan het einde best gretig. Dat is wel een goed teken, denk ik.
Zoals eerder geschreven zijn de twee taperweken niet ideaal. Zo had ik veel last van een wortelkanaalbehandeling en uiteindelijk het trekken van kies. Vooral de naweeën van die laatste ingreep, die uiteindelijk beter door een kaakchirurg dan door een tandarts uitgevoerd had kunnen worden, duren nog steeds voort, maar de pijn neemt inmiddels wel wat af en ik neem alleen nog in de avond pijnstillers. Daarbij komt dat ik een ontsteking van de peesschede in mijn linkeronderbeen heb en al is die nog niet verdwenen – het gaat wel de goede kant op. We gaan het zien op Texel.
Lastig is te bedenken op welk tempo ik aanstaande zondag wegga. Uiteindelijk zullen het parcours en de omstandigheden een grote rol spelen, maar het is toch wel fijn iets van een richttempo/-tijd hebben, denk ik. Op de website van de Zestig van Texel geeft Gerrit van Rotterdam in zijn trainingsgids de onderstaande tabel met verwachte eindtijden op basis van (weg)marathontijden.
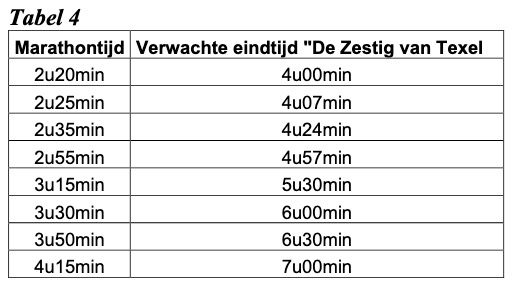
Verwachte eindtijden Zestig van Texel (bron: Van Rotterdam, Gerrit. Trainen voor de Zestig van Texel.
Omdat er een beperkt aantal marathontijden in staat, heb ik een klein calculatortje gemaakt dat op basis van een zelf in te voeren marathontijd een voorspelling geeft die overeenkomt met de genoemde tabel.

Zestig van Texel-calculator
Het gaat expliciet om schattingen. Ik houd me dus niet verantwoordelijk voor de voorspellingen of de gevolgen daarvan. Kijk uit en staar je niet blind op de voorspelde tijd! Dat prent ik mezelf ook in.
Je kunt de calculator gebruiken op https://www.reuneker.nl/files/zestig.