The Hirsch-Popescu Point (Popescu & Altmann, 2006) is an interesting metric to assess repetition in a text. It is determined by first calculating the frequency distribution of all words in the text. Then, words are ranked from the most frequent to the least frequent. The H-P Point is then defined as 'the point in which the ranking of a word in the distribution matches its frequency, just like the h-index in academia' (see Nunes, Ordanini, Valsesia, 2017, p. 20; Hirsh, 2005). Indeed, the h-index is a well-known measure of productivity and citation impact of publications. The smaller the H-P point, the less repetition a text contains and vice versa, i.e, the greater the HP-point, the more repetition a text contains.
If we apply the calculation to an example text, we easily see how it works exactly. The text used here is Sylvia Plath’s poem 'Lady Lazarus' (1965), and the resulting frequency table (distribution of words) can be seen below.

Word distribution in Sylvia Plath’s poem ‘Lady Lazarus’ (1965)
In this table, we see that the word of occurs eight times in the poem, and it is also ranked at position eight in order from most to least frequent words. Therefore, 8 is the H-P Point. Of course, this frequency table, the sorting and determining the actual point at which frequency and order coincide is done by the Lexical Diversity Calculator for you, as can be seen below.
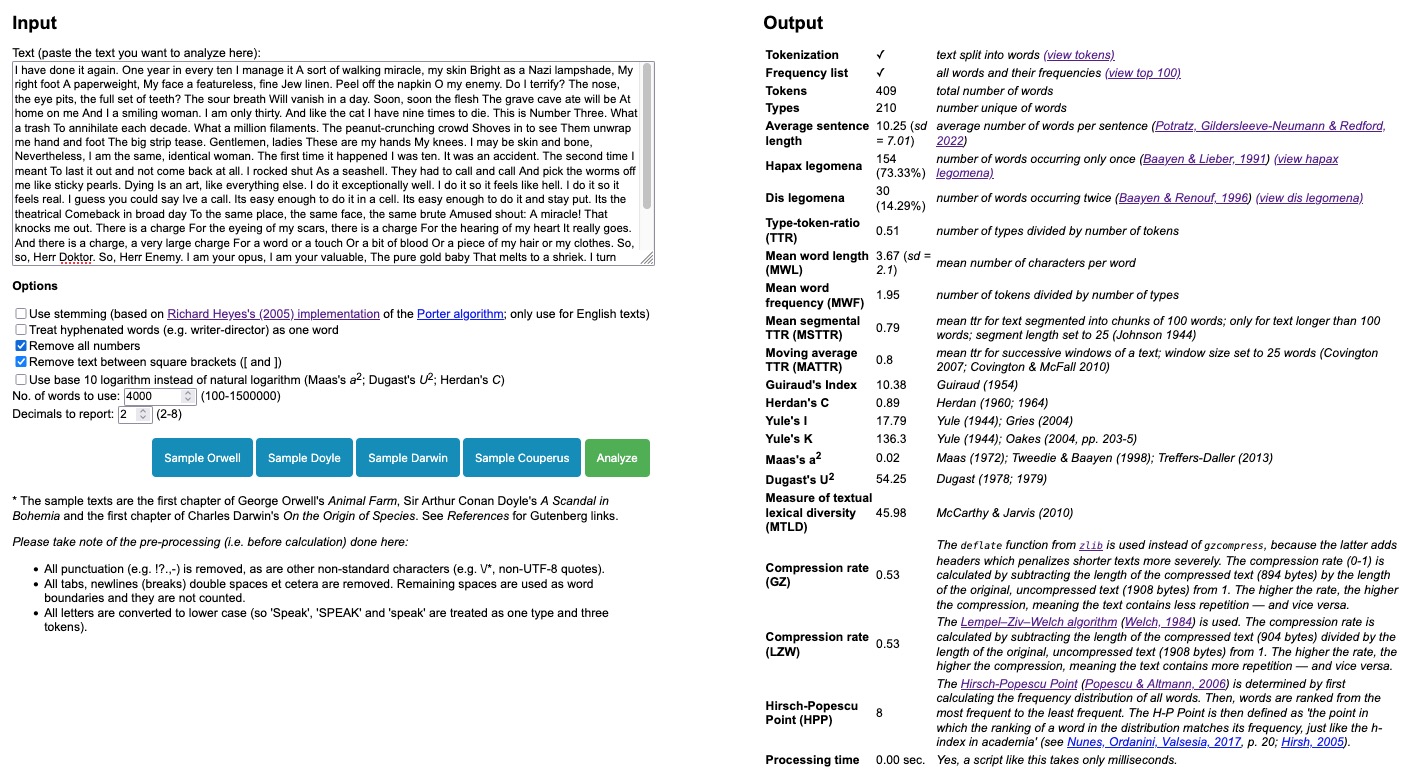
The Hirsch-Popescu Point as calculated by the Lexical Diversity Calculator
As always, if you find it useful, have fun!



