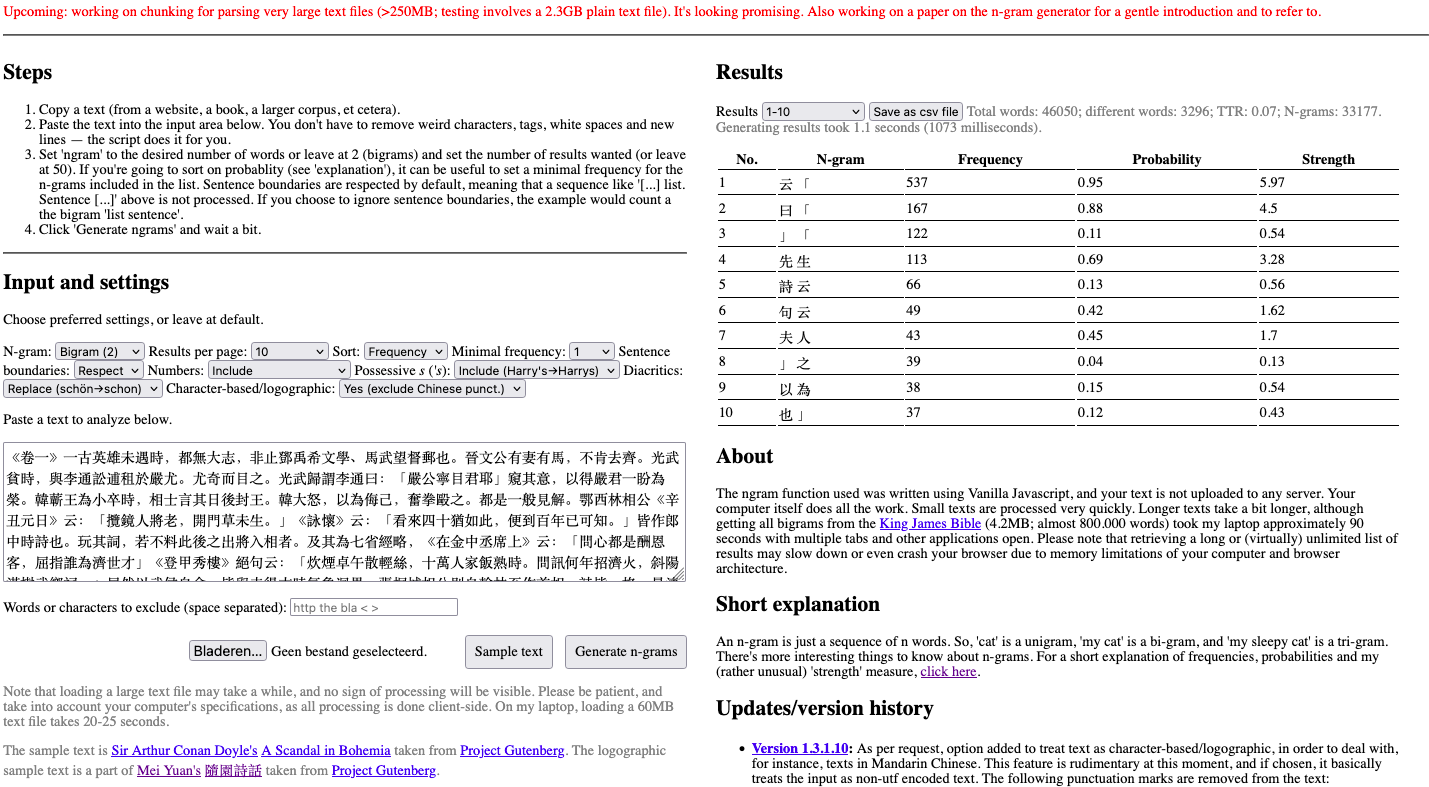
As per request, I have added an option to the n-gram generator to treat text not solely as word-based, but also as character-based/logographic text. This enables analyzing texts in, for instance, Mandarin Chinese.
Logographic n-grams in the n-gram generator
As my knowledge of character-based languages is virtually non-existent, the feature is rudimentary at this moment, although two researchers of Mandarin Chinese did test the tool and evaluate the output. With respect to Chinese, a limitation pointed out to me by Maarten Bogaards, is that the character-based script does not have spaces, and the calculator basically treats each individual character as one word, even though words can consist of multiple characters. A Chinese sample text to test with can now also be loaded, and is a sample of Mei Yuan's 隨園詩話, taken from Project Gutenberg.
One of the things I added after testing was the removal of following punctuation marks, which are different in Chinese, namely 。,、“‘’”《》…·:?!;()and ,. You might not see the difference in all marks, but they are non-utf-8 counterparts, which, for computers at least, are a different beast. You can also enter additional characters to exclude if you so wish.