I added the Flesch-Kincaid Reading Ease Score (FRES) to the Lexical Diversity Tool. This metric calculates the difficulty of a texts based on the number of syllables, words and sentences in a text. The lower the score, the more difficult a text is to read. In the screenshot below you'll see the Flesch-Kincaid Reading Ease Score for the text Minder eten weggegooid dan eerdere jaren for a Dutch news text for children (Jeugdjournaal). Compared to the news text for the same topic, but written for Dutch adults, the Flesch-Kincaid Reading Ease Score is much higher (73.41 vs 46.65 respectively).
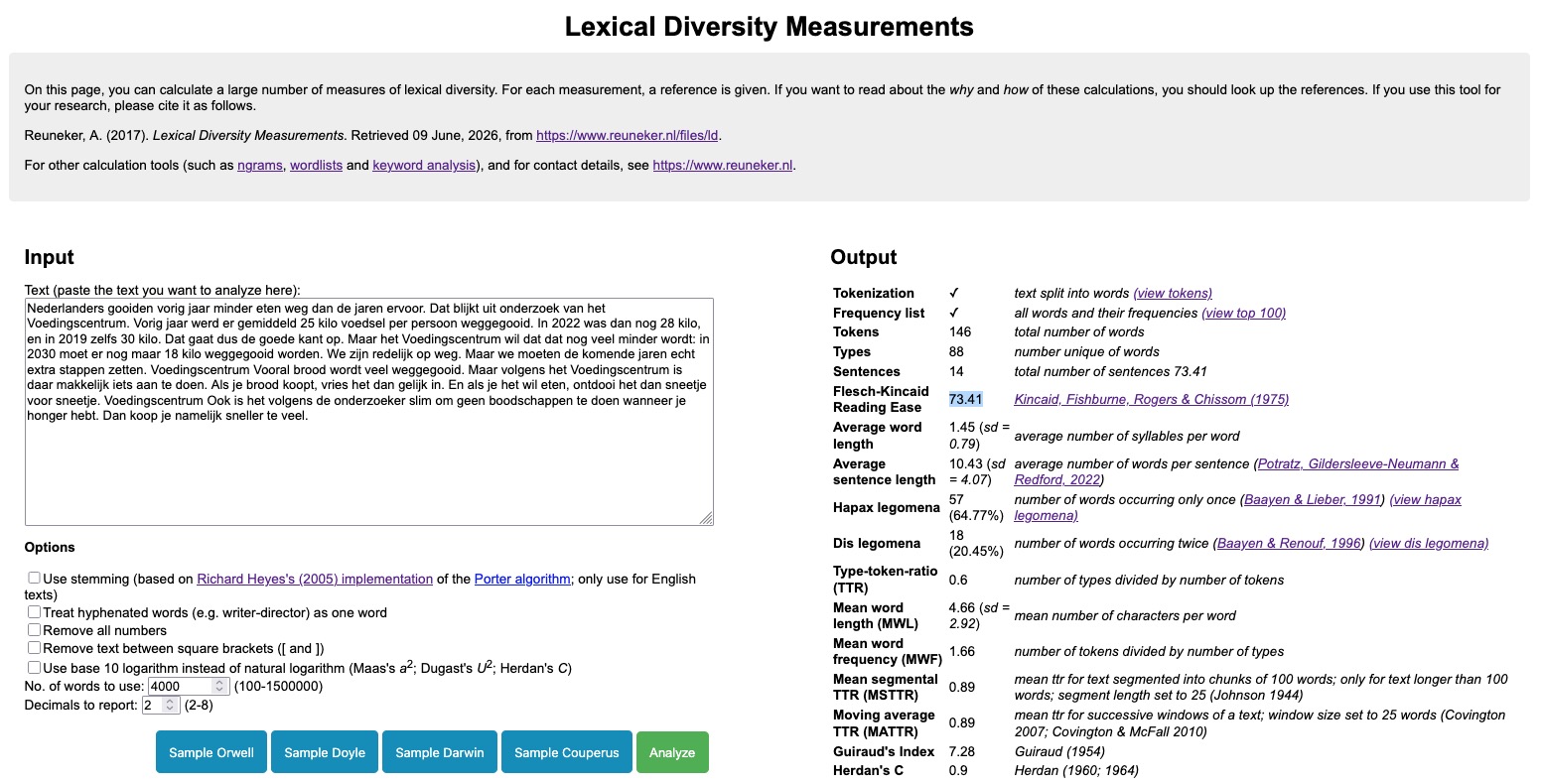
Flesch-Kincaid Reading Ease Score
The tool now also list the number of sentences in a text, as well as the average word length in number of syllables, and (optionally) a list of words and their number of syllables. The measure only works for Dutch texts (for now), because the (still imperfect, but good enough) splitting up of words into their syllables is based on the Dutch language. You can check it out now at https://www.reuneker.nl/files/ld.
A last note is that I am contemplating taking readability measures like this out of the Lexical Diversity Tool, because lexical diversity and readability are related, but certainly not the same. The tool also becomes a bit chaotic and cluttered, so the more reason to give readability its own calculator page some day.