Op 23 mei brak ik mijn sleutelbeen doordat ik een overstekend konijn raakte en viel. Heel vervelend, maar het herstel gaat, zeker na de operatie, heel goed. Tijdens het genoemde rondje was het plan een in het vroege voorjaar verloren AirTag terug te halen; die schoot zo uit mijn (nieuwe) HideMyBell. Ik heb het even gecheckt — ik verloor de AirTag op zaterdag 11 april 2026. De AirTag bleek, een maand later toen ik me afvroeg waar dat ding toch eigenlijk was, nog te werken. Maar ja, tijdens dat rondje om ‘m te zoeken, brak ik dus mijn sleutelbeen en inmiddels is er weer een flinke tijd overheen gegaan. We zitten immers al diep in juli.
Nu reed ik vandaag een rondje met mijn vrouw (E, vandaar) en we zouden praktisch langs de AirTag komen, dus waarom niet even zoeken? Het kleine apparaatje was volgens de telefoon immers nog steeds actief en zou nog steeds op dezelfde plek liggen. Bizar, na maanden regen en uitersten van nachtvorst tot 40 graden en felle zon1 Het kostte even moeite, maar met het geluidje dat je vanaf je telefoon kunt activeren, hebben we de AirTag toch gevonden in het inmiddels hoge gras en de doornenstruiken.
Teruggevonden! De AirTag die, na dik 100 dagen/14,5 week in weer en wind, nog werkte.
En inderdaad, hij doet ’t gewoon nog — zelfs het geprinte stickertje zat er nog op. Hoewel ik niet per se erg gehecht ben aan een AirTag, werd ik wel blij van de gezamenlijke zoektocht en natuurlijk de goede afloop.
Op basis van een telefonisch interview met journalist Joppe Gloerich word ik genoemd in het artikel Het rijmt niet, maar het klinkt wel (goede titel!) in de zomerspecial ‘Lezen & Luisteren’ van Elsevier Week Magazine. Het is een leuk stuk geworden, al klopt de uitspraak/het citaat niet en staat er een verkeerd aantal jaren in (zeventig in plaats van zestig jaar aan popmuziek). Toch is het leuk om geïnterviewd te worden en dan in een gedrukt blad te staan.
Zomerspecial ‘Lezen & Luisteren’ van EW Magazine.
Het stuk staat helaas achter een betaalmuur, dus het moet óf gekocht worden, of je zult het moeten doen met het korte stukje hieronder. Veel leesplezier!
Fragment uit ‘Het rijmt niet, maar het klinkt wel’.
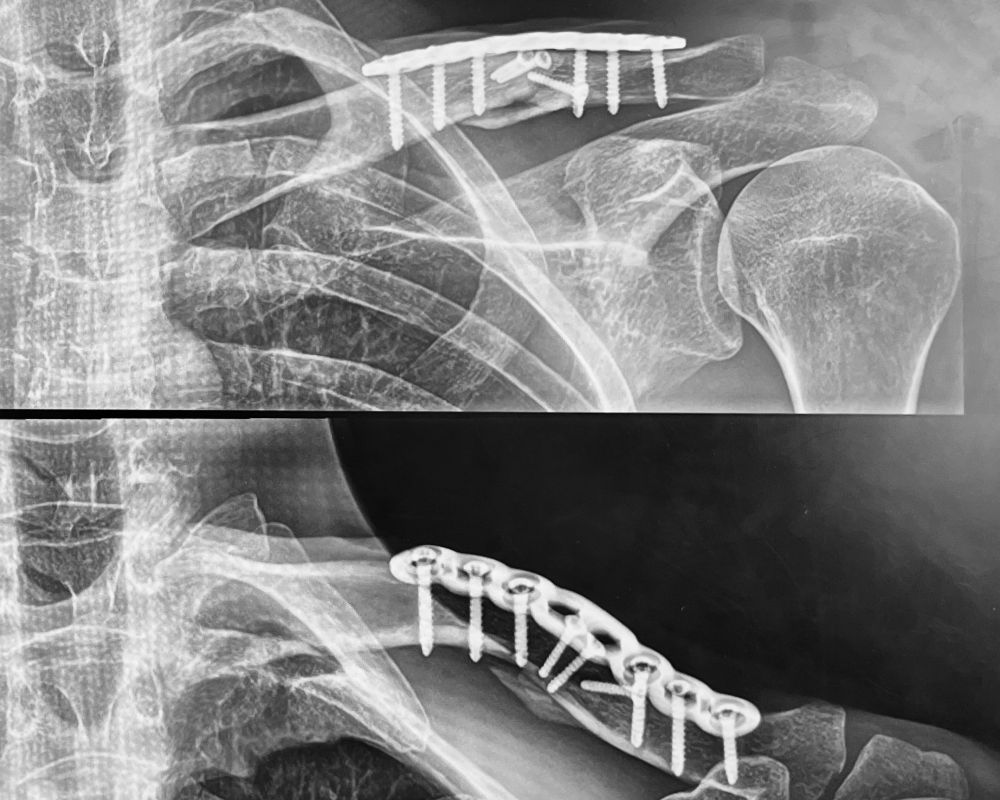
Een kleine zes weken na de sleutelbeenoperatie mocht ik voor controle terug naar de arts — eerst een nieuwe röntgenfoto, daarna een gesprek. Aangezien de arts die de operatie uitvoerde van tevoren zei dat ‘de test’ zou zijn hoe hoog ik mijn linkerarm weer zou kunnen strekken en ik die inmiddels weer bijna even hoog als rechts kon bewegen, verwachtte ik geen problemen. Die bleken er, gelukkig ook niet te zijn. Het litteken ziet er netjes uit, ik heb alleen nog echt last na een nacht slapen op de linkerkant en met de beweging zit het dus wel goed. De enige beweging waarin ik nog echt beperking voel, is die naar achteren, maar dat wordt ook steeds minder merkbaar.
Al met al ben ik, eigenlijk al nadat de twee dagen naar voelen van de narcose voorbij waren, vooral erg dankbaar en gelukkig, want de operatie had direct effect. De twee delen van het sleutelbeen stonden weer goed en konden niet meer afzonderlijk bewegen. Voor andere wielrenners die hun sleutelbeen hebben gebroken en die door googelen wellicht hier terecht zijn gekomen: bij iedereen zal het best een beetje anders uitpakken, maar ik ben heel blij met de operatie!
Sleutelbeen ongeveer 5,5 weken na de operatie.
Overigens vind ik het titanium/chirurgisch stalen ‘plaatje’ en vooral de schroeven vrij grof ogen, maar dat schijnt heel normaal te zijn. Ik kon het beeld van een doosje Gamma-schroeven echter maar met moeite onderdrukken.
Zoals eerder te lezen viel, was ik nou niet echt te spreken over de Garmin-houder van HideMyBell voor de racefiets. Bij de eerste keer bellen vloog de bel eraf en verloor ik, zo ontdekte ik veel later, de tussen Garmin en bel gemonteerde AirTag. Exit HideMyBell dus. Ik was al een tijdje op zoek naar een nette oplossing om toch een bel op de racefiets te hebben, want op zich had ik me jaren beholpen met een getiewrapt belletje, maar het oog wil natuurlijk ook wat. Het blijft een luxepaard, zo’n Italiaanse racefiets.
Afgelopen week kreeg ik, heel toevallig, een mailtje van de fabrikant van mijn huidige Garmin-houder, JRC Components, met een set om een bel onder de Garmin te monteren. Het gaat om de Underbell(y) Integration Kit, bestaande uit een mooi adaptertje van aluminium en een zogenaamde Knog Oi-bel, zoals je hieronder kunt zien.
Underbell(y) Integration Kit, JRC x Knog
Voor een fietsbel was het veel geld (met wat korting en de verzendkosten 36 euro), maar echt duur is dat mijns inziens niet, want de Knog Oi kost lost al €29,99. Installeren was een fluitje van een cent en hoewel ik de eerste echte test afwacht — een bel moet blijven zitten en lekker luid zijn — vind ik lekker onopvallend en gewoon mooi. Dat is alvast wat waard.
Tijdens een whiskyproeverij afgelopen zaterdag hoorde ik de ‘whisky-gids’ de volgende zin zeggen: ‘Als je van hout houdt, houd je van hout.’ Dat was natuurlijk een cadeautje voor een taalkundige met al een paar kleine, maar straffe slokjes whisky achter de kiezen. Enigszins jolig vroeg ik de gids die zin te spellen, maar hij kaatste de vraag terug en gelukkig lukte het mij nog prima. Het is wel echt een leuke zin, omdat je naast natuurlijk het zelfstandig naamwoord hout het homofone (gelijkklinkende) werkwoord houden zowel na het onderwerp in de tweede persoon je hebt (‘als je… houdt’ met een t), als ervoor (‘houd je van…’ zonder t). Uit de resultaten van eerder onderzoek met Mette Rebel (2025) weten we inmiddels hoe moeilijk die vormen gevonden worden.
Mocht je je trouwens afvragen waarom het over hout gaat tijdens een whiskyproeverij: de houten vaten waarin whisky opgeslagen wordt en rijpt, is van grote invloed op de smaak.
Al jaren verbaas ik me erover dat ik, zelfs als ik goed in vorm ben voor bijvoorbeeld een marathon, soms nauwelijks de trap lijk op te komen. Gelukkig is dat wat overdreven, maar traplopen voelt altijd wel zwaar en helaas maakt mijn hoofd daar dan, zeker als er een hardloopwedstrijd in het vooruitzicht is, van dat het toch minder goed met de conditie is gesteld dan gedacht of gehoopt.
Toevallig stuitte ik op vandaag op dit leuke, interessante (en gratis te lezen) artikeltje op de website van Quest: Waarom is traplopen zo zwaar, zelfs als je een goede conditie hebt? Ik zal niets verklappen, maar het aangehaalde onderzoek laat zien dat de koppeling met algemene conditie zeker niet zonder meer opgaat. Geruststellend wel, vind ik.
Gisteren liep ik met een mixteam van het werk van mijn vrouw de Ekiden bij PAC — een jaarlijkse wedstrijd waarbij je met zes lopers een marathonafstand (42.195km) aflegt. De individuele afstanden liggen vast: 5, 10, 5, 10, 5 en 7.195km. In het wisselvak op de baan geef je de tasuki, het lint met chip voor tijdregistratie, aan elkaar over en loop je nog een kleine honderd meter door tot de start-/finishlijn.
Shirt Ekiden 2026
Van tevoren wist ik dat er door warmte en vooral de sleutelbeenoperatie, het herstel daarvan en het minder kunnen trainen, niet heel veel in zat, maar ik moest voor m’n gevoel toch nog wel aardig wat moeite doen om onder de 38 minuten te blijven. Last van mijn sleutelbeen had ik niet echt, behalve dan dat de tasuki wat over het litteken schuurde, maar ik merkte vooral dat mijn ribben ook een klap hebben gekregen. Als je dan een wat langere tijd een hogere inspanning levert, merk je dat wel. Het viel me qua inspanning, als ik eerlijk ben, best tegen. Raar is dat wel, want ik had van tevoren bedacht dat ik zo’n beetje mijn oude marathontempo zou proberen te lopen, tussen de 3:45 en 3:50 per kilometer. Ik liep de 10 kilometer in 37:53, met een gemiddelde van 3:47, dus eigenlijk heb ik precies kunnen doen wat ik had bedacht. Toch was het lastig te accepteren dat dit, op deze dag, dus mijn 10K-tempo was. Wat overigens niet geholpen zal hebben, was de eveneens warme duurloop van gisteren… lastig, die planning. Fijn was dan weer wel dat ik de tweede helft wat sneller liep en dat de tweede ronde ook beter voelde. En nog meer in de categorie mooi: mijn vrouw liep een heel mooi PR van 22:54 op de 5 kilometer!
Op naar de finish van de Ekiden 2026. (Helaas kon ik geen foto’s van ons team of de andere leden vinden.)
Belangrijker misschien nog wel was dat het een heel gezellige dag was — we hebben als team een mooie tijd beleefd en neergezet: 3:09:15, waarmee we 27e waren van de 272 mix-teams en 74e van alle 392 teams. Sowieso was het mooi om te zien hoe ontzettende groot de Ekiden is geworden en hoe goed en ongedwongen de sfeer was, zonder het wedstrijdelement uit het oog te verliezen. Ondanks de festivalachtige sfeer was een snel startvak en er werd serieus hard gelopen. Iedereen die ik sprak — veel oude bekenden, onverwachte collega’s van eigen werk — had last gehad van wind en benauwdheid, maar omdat je voor en/of na het hardlopen ook op elkaar aan het wachten bent, was het mooie weer ook heel fijn.
Precies vier weken na de sleutelbeenoperatie en vijfeneenhalve week na de val vond ik het gisteren tijd om een mooi, maar rustig en bescheiden wielertochtje te maken. Niet omdat het vier weken geleden was, maar vooral omdat mijn sleutelbeen al snel na de operatie stukken beter voelt, ik mijn arm weer bijna helemaal omhoog krijg en alleen de beweging naar achteren nog beperkt is. Het doet ook geen pijn meer, al vermijd ik nog elke krachtinspanning met links.
Wat ik vooral vreesde, was de positie op de fiets en de trillingen op de weg. De positie op de fiets kon ik op zolder op de fietstrainer wel wat nabootsen, maar op de virtuele wegen heb je natuurlijk geen last van oneffenheden in de weg, je hoeft geen bochten te maken et cetera. Het werd dus echt een testrondje.
Het voelde geweldig — het was heerlijk weer en ik koos een bekend rondje zonder risico’s, al moet ik zeggen dat het enige waar ik last van had toch een beetje angst was voor konijnen en andere dieren op stukken langs bermen en bosjes. Dat zal moeten slijten, denk ik. Verder gaf het klassieke rondje Hoek van Holland — met koffie aan het strand zo op de heflt — vooral een bevrijdend gevoel.
Koffie aan het strand
Ook leuk: ik parkeerde de fiets op een vanaf het terras zichtbare plek, waarna de serveerster direct op me afliep en vroeg ‘ze is er al, wil je koffie?’ Ik stond er wat suf bij te kijken, want ik had geen idee wie of wat ze bedoelde. Er bleek een vrouw op het terras te zitten die een nogal gelijkende fiets had, maar ik kende haar niet. (Voor de leek zijn de fietsen bijna identiek, maar zij had de Bianchi Oltre Race en dat ging mijn budget te boven.) Het leverde een leuk gesprekje op over, hoe kan het anders, fietsen (zowel het zelfstandig naamwoord als het werkwoord) en wat restte was slechts nog de weg terug, langs het water met de wind in de rug. Een geslaagde test!
Sometimes, properly aligning tab music in Word or any such program can be quite a pain. Mostly for my own use in playing harmonica songs, but free and open to anyone, I made a small webpage this morning that does just that: align tab music, or lines with notes and, if you want, words underneath.