Nog een kleine toevoeging aan de Lexical Diversity Calculator: je krijgt nu, na het analyseren van je tekst, ook de gemiddelde zinslengte (in woorden) en de gemiddelde woordlengte (in letters/tekens). (Ook de standaarddeviaties worden daarbij gerapporteerd. Zie overigens Grzybek, 2014 voor een interessant literatuuroverzicht over woordlengte.) Voor sommige onderzoekers is dat nuttig, bijvoorbeeld om te kijken of kinderen steeds langere woorden en zinnen kunnen begrijpen (zie bijvoorbeeld George & Tomasello, 1984 en, een stuk recenter, Potratz, Gildersleeve-Neumann & Redford, 2022).
Een simpel voorbeeldje. Zowel de website van de NOS als de website van het Jeugdjournaal rapporteert over de bekendmaking van het nieuwe goede doel van 3FM Serious Request.
(Afbeelding verwijderd.)
De gemiddelde zinslengte in het NOS-artikeltje is 15.89 woorden en in het Jeugdjournaal-artikeltje 10.75 woorden. Wat betreft woordlengte is die bij de NOS 5.15 letters, bij het Jeugdjournaal 4.76 letters.
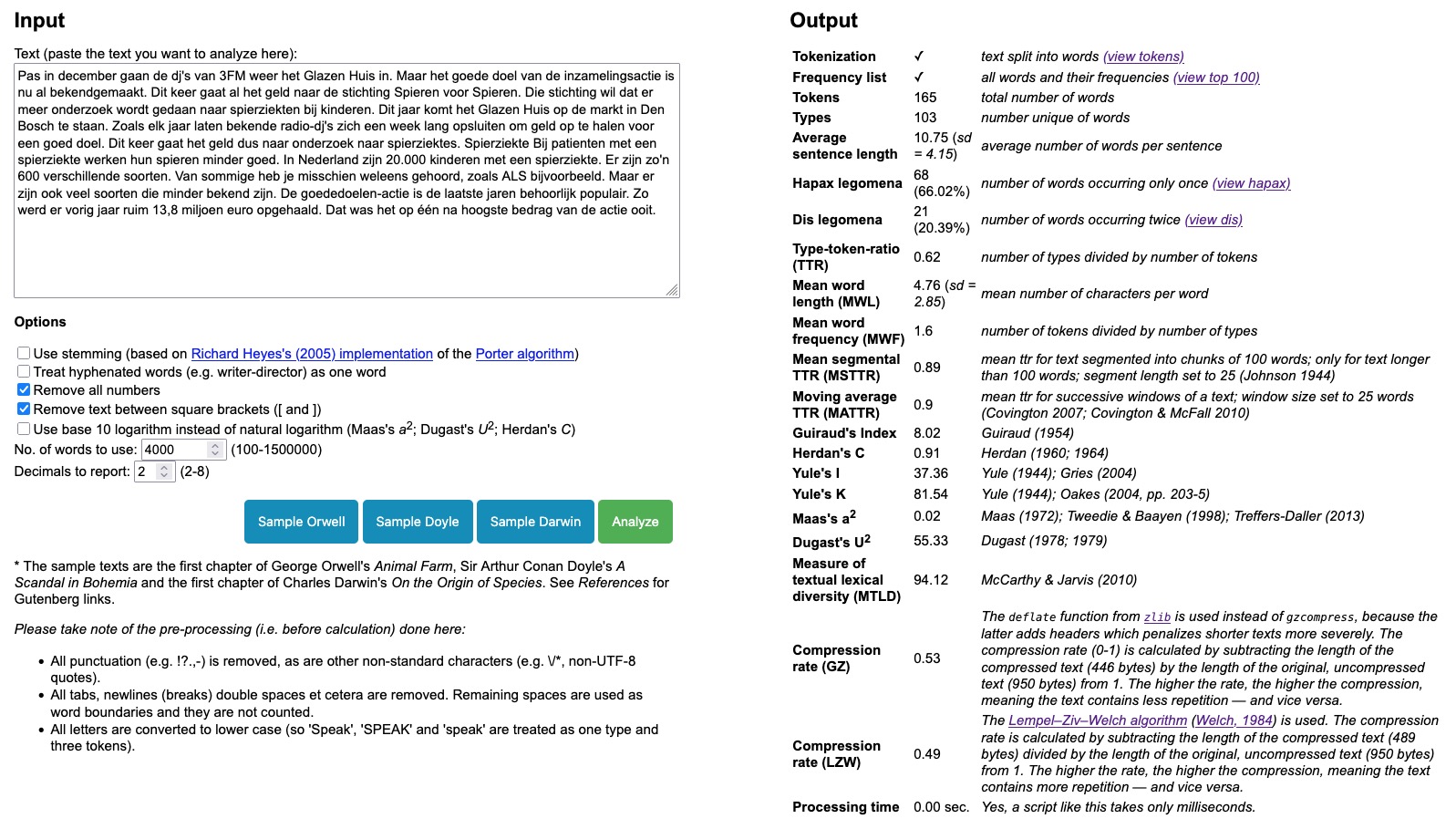
Analyse van het Jeugdjournaal-tekstje over 3FM Serious Request
Zinnen en woorden in teksten voor volwassen lijken dus inderdaad langer dan in teksten voor kinderen. De artikeltjes zijn echter veel (en veel!) te kort om echte uitspraken op te kunnen baseren (niet representatief, hoge standaarddeviatie uiteraard), maar dit was dan ook slechts een simpel en klein voorbeeldje.



